
Hi, I’m excited that there are so many people interested in learning more about how and why to run SQLite in production.

Let me start by introducing myself. My name is Stephen, and you can find me on Twitter (no, I will not call it X) at fractaledmind. I am an American who moved to Berlin Germany 5 years ago, and in only a few more weeks I get to marry my fiancé, who is a Russian who moved to Germany around 10 years ago. She is actually here today, and this is her first time seeing me give a conference talk. So, no pressure, right?
At my day job, I am the head of engineering at Test IO, which is a crowd-driven testing service. Then, in my spare time I am an open source developer, actively contributing to and maintaining a number of gems. I also write a fair bit on my blog as I go.

Today I want to talk about why this is how I start all of my new Rails projects, and why you might want to as well.

Specifically, I want to discuss why it might make sense to choose SQLite as your database engine. In fact, I want to even suggest that you might lean on SQLite for all of your app’s data needs. Now, whenever I suggest using SQLite in production for web applications, the primary and most common question I get is…

Why? So, let’s explore that together. Who here is running or has run an application in production with SQLite? Who has experimented with SQLite for an app, but not shipped it to production? There are a couple hands up, but not many. So, let’s turn this question around.

Why not use SQLite in production? What are some of the reasons you haven’t considered SQLite as an option?
Well, the primary reason I choose SQLite is that it allows me to build useful and valuable applications quickly and to maintain them easily.

In his RailsWorld keynote, DHH re-emphasized the point that Rails, at its core, is “the one-person framework”. It aims to be a bridge over complexity that allows even the smallest possible team—only you—to build full, rich, valuable web applications. And I believe that SQLite aligns perfectly with that vision. There are 3 basic reasons…

First is that SQLite is simple. The database is a literal file on disk. The engine is a single executable. Every aspect of the database can be fully embedded into your majestic Rails monolith.

Next, this simplicity grants you unique control. When both the storage and the engine for your database are embedded in your app, their configuration naturally lives in your app as well. Plus, because SQLite is a single executable, it is possible to fine-tune the actual compilation of that executable through Bundler. Then, having your database simply be a file permits novel and powerful developer experiences, like branch-specific databases.

Finally, SQLite is fast. When your data lives on the same machine as your application, you eliminate all network latency. You go from measuring queries in milliseconds to microseconds. Microseconds. Now, that being said, I know that there is a presumption that SQLite isn’t actually fast for web applications. One of my goals for this talk is to dispel this myth and show you that a well-tuned SQLite installation is plenty fast to drive your next big idea.

So, that is why you should consider using SQLite in production, but the real heart of the matter is how.

And let’s start where all projects start — with building an MVP.

As I said, this is how I start all of my projects lately. And once you generate your basic Rails skeleton, all you need to do is, well, build your actual application. In an earlier iteration of this talk, I was actually going to walk thru the details of building an MVP with you. But, eventually I realized that this was completely off-topic. None of the details of the MVP were specific to SQLite, and any of the details of how I organized or structured the code are distractions.

So, instead, I want to just show you a very simple MVP that I have built for this talk. We can then use this codebase as the playground for exploring how to leverage some of SQLite’s unique powers to improve our application.

- show the codebase
- switch to the browser to explore the demo app
So, that is the basic MVP that we will be working with today. It is a SQLite on Rails application that we have gotten the core functionality implemented and running on our machine. The next step is getting this application running in production, on the internet.

So, how do we deploy SQLite on Rails applications? The first and maybe most important detail here is that Heroku isn’t an option. Any hosting provider that only provides an ephemeral file system won’t work as a host for a SQLite on Rails application. Luckily though, there are a number of different hosting providers that do provide some form of persistent disk storage. fly.io, Render, and Hatchbox are two of the most popular ones in the Rails ecosystem, but I know there are others.

I personally have used (and loved) Hatchbox for years. So that is what I use, and that’s what I want to show you today. Hatchbox is essentially an “Ops-as-a-Service”. You bring your own server, whether a DigitalOcean droplet or a Hetzner VPS or something else, and their platform will configure the server, deploy the repo, and generally take care of going from “I don’t have an app on the internet” to “I do have an app on the internet”.
This is another occasion where I originally wanted to walk you thru deploying our app live, but after doing it a couple of times in preparation, I realized that I didn’t want to have us all just sitting here waiting for a server to be provisioned. So, I instead documented literally every single step and screen of the process. So, let’s walk thru a simulated live demo of deploying our MVP application to production.
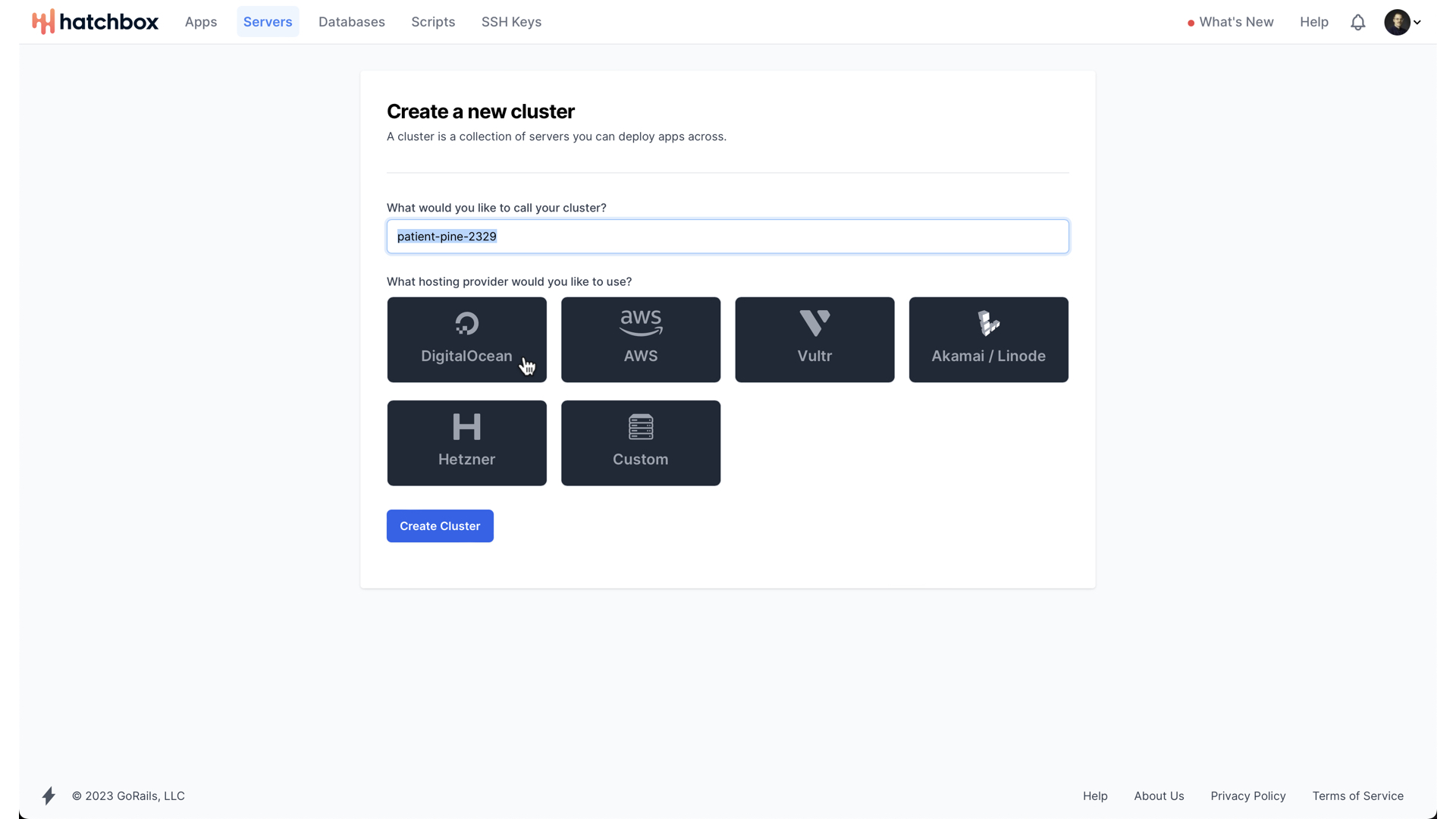
When you begin, you need to create what Hatchbox calls a “cluster”. They need to support applications that have maybe 3 servers running instances of the web app, two different servers running two different instances of Redis, each with different eviction policies, and one primary database server alongside one replica database server. Thus, they have clusters. One of my favorite aspects of a SQLite on Rails application is that we don’t need a complex network of interconnected servers to run our application. And especially at the beginning, when just trying to create something from nothing, being able to get a fully-functioning application without having to figure out all of these operational details can be the difference between shipping in days vs shipping in months. Anyway, we will create our cluster, and use DigitalOcean as our hosting provider. In the end, our cluster will only have one server, but we need to conform to Hatchbox’s view of the world nonetheless.
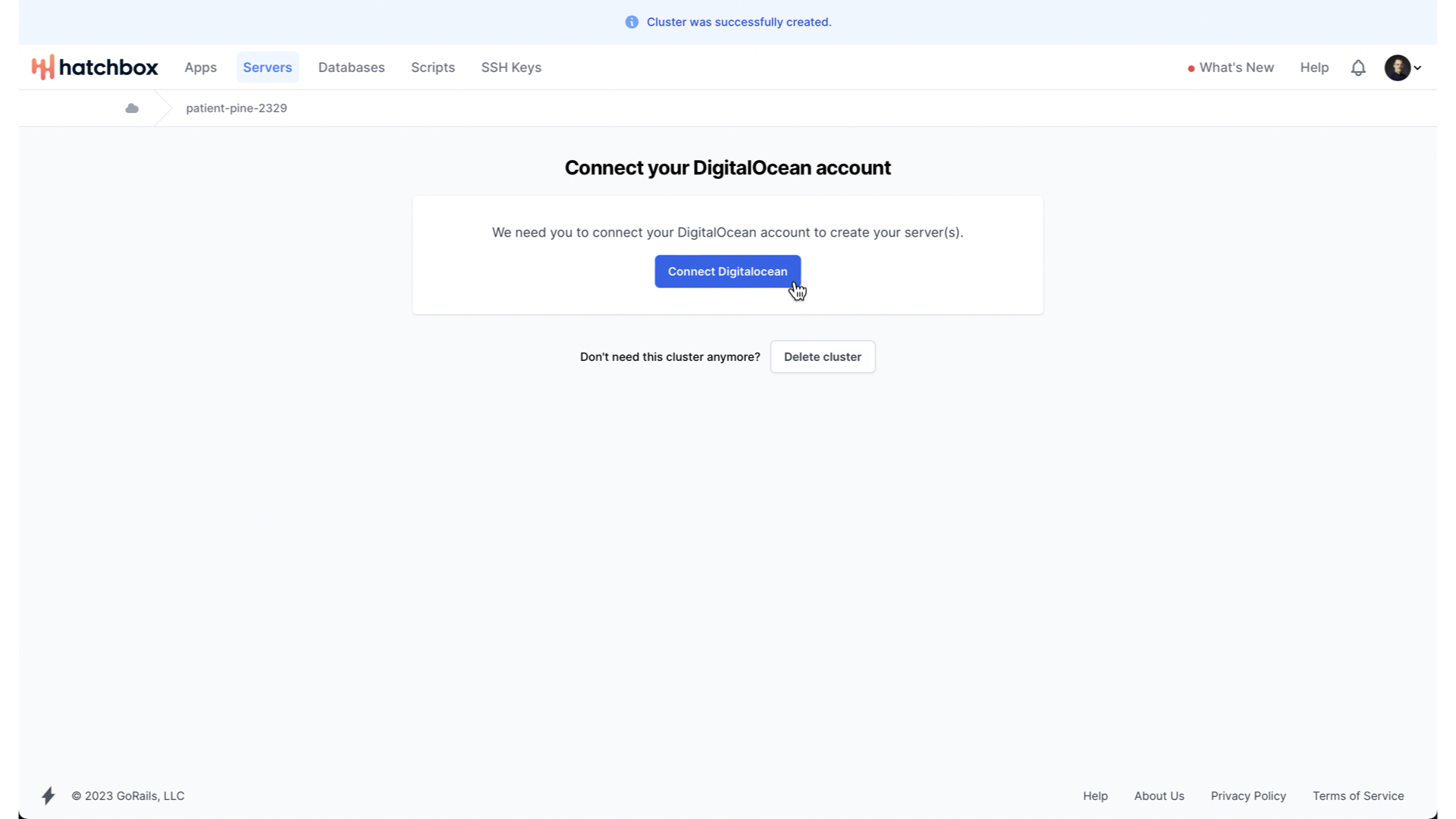
We then need to connect our DigitalOcean account, to grant Hatchbox the ability to manage our DigitalOcean droplets on our behalf.
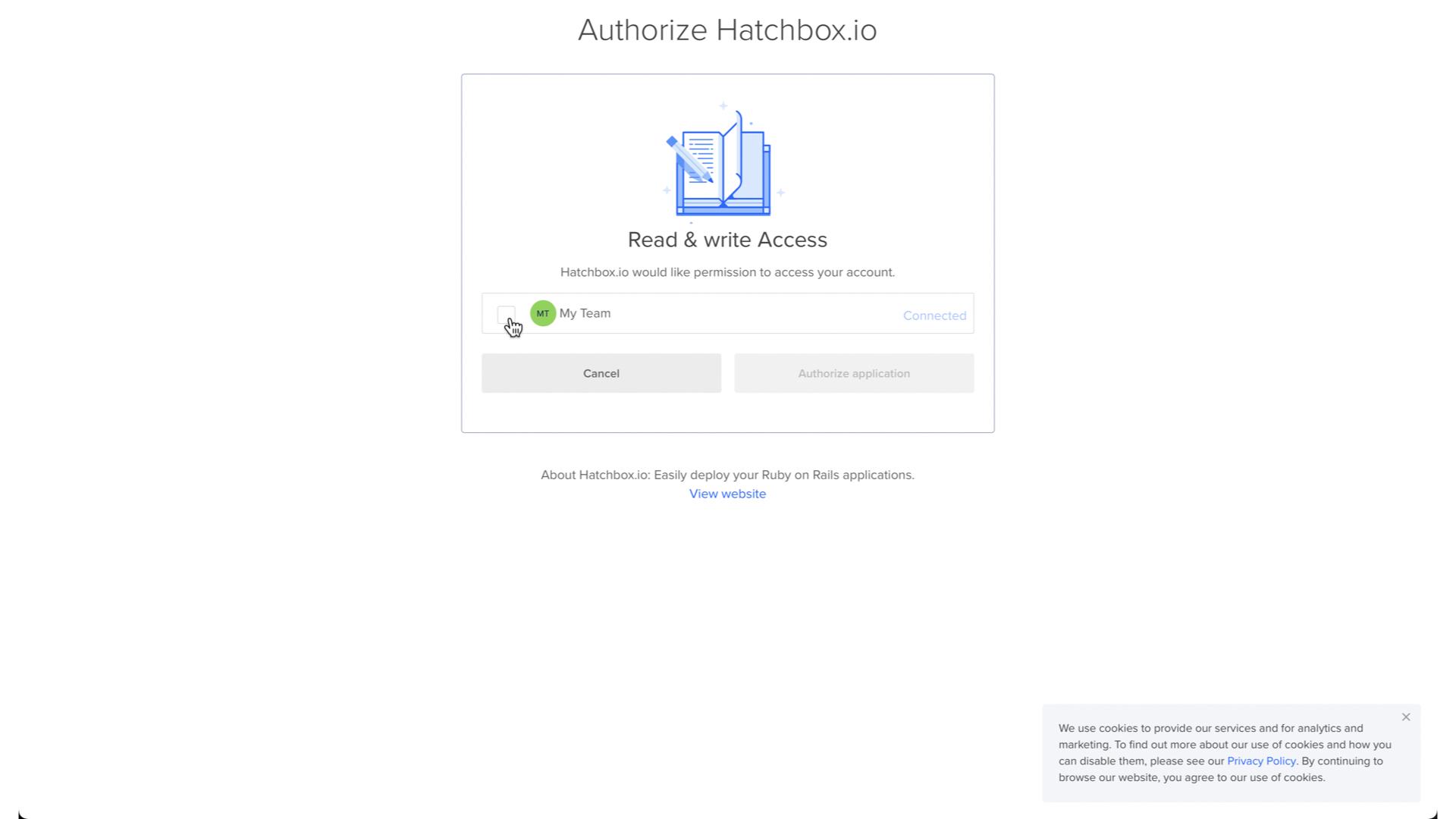
This will take us to a DigitalOcean OAuth page where we authorize Hatchbox for whichever DigitalOcean team account we want.
Once we have authorized Hatchbox,
We can start configuring our cluster. We first need to choose the region that our cluster will be hosted in.
DigitalOcean offers a number of different region options.
Let’s choose Frankfurt for now. Pretty nicely centrally located.
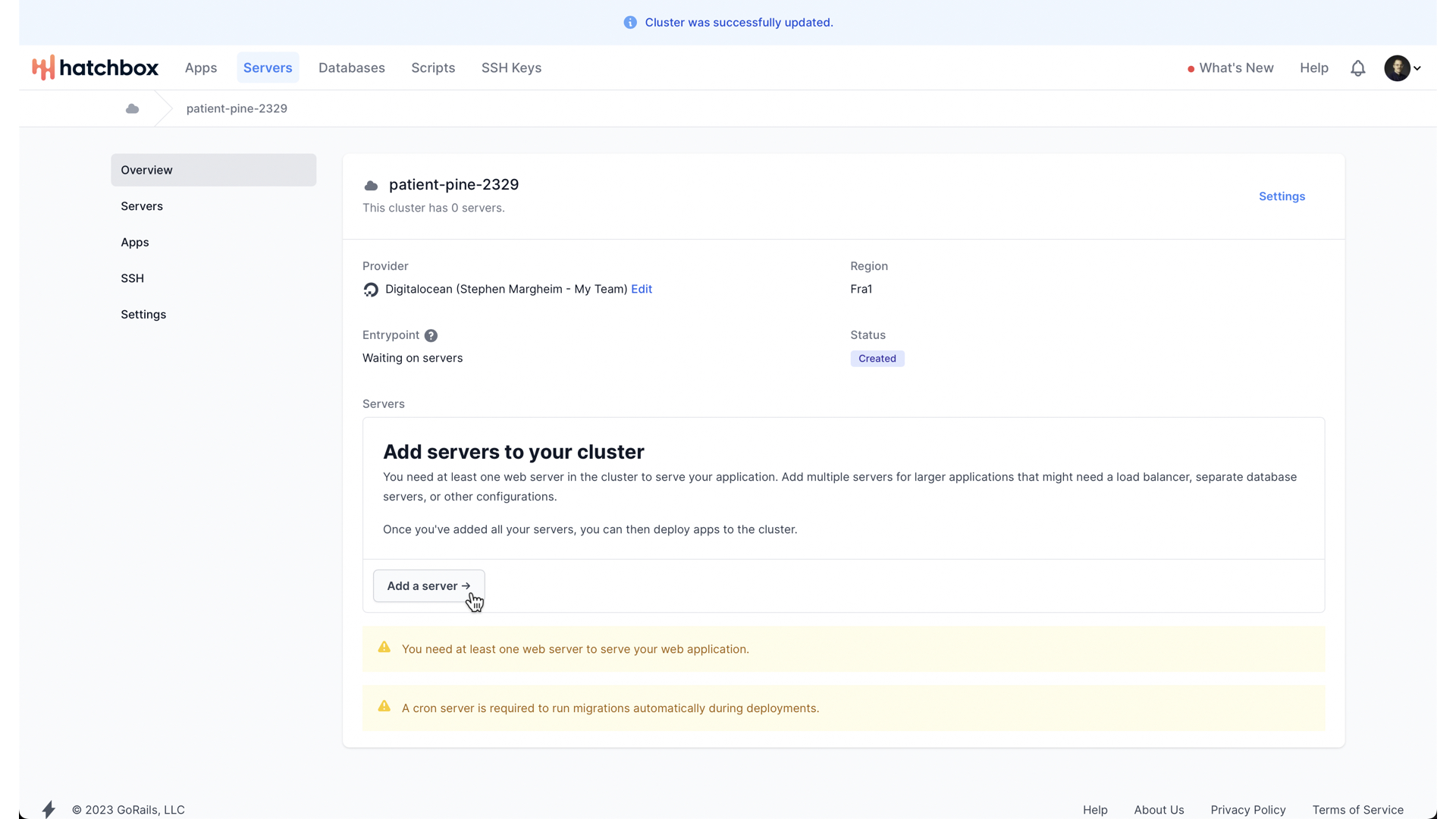
With that, our cluster is created, and so we need to add a server to our cluster next.
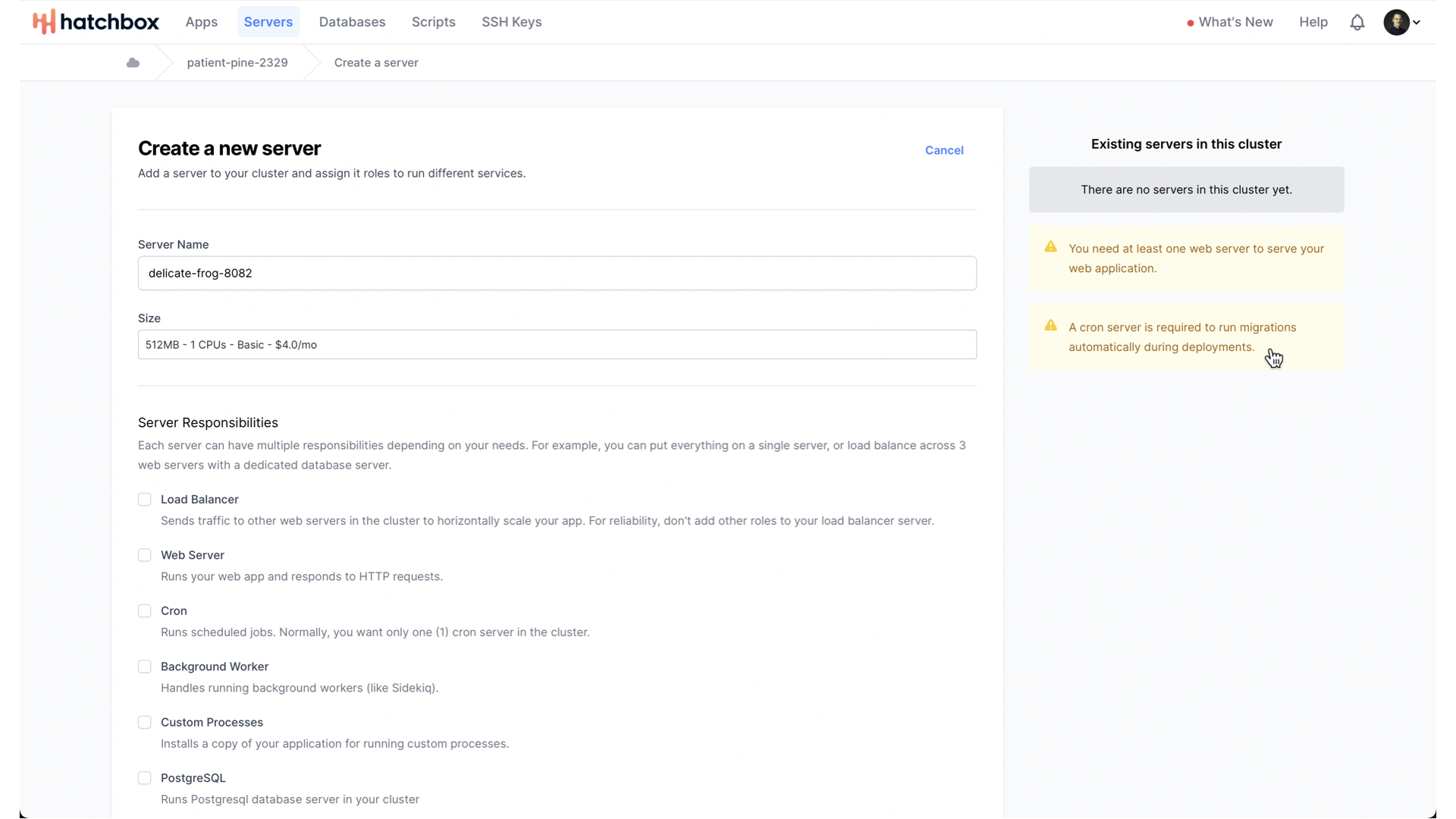
As Hatchbox will remind us, we minimally need a server with two core responsibilities—run our web app and run cron.
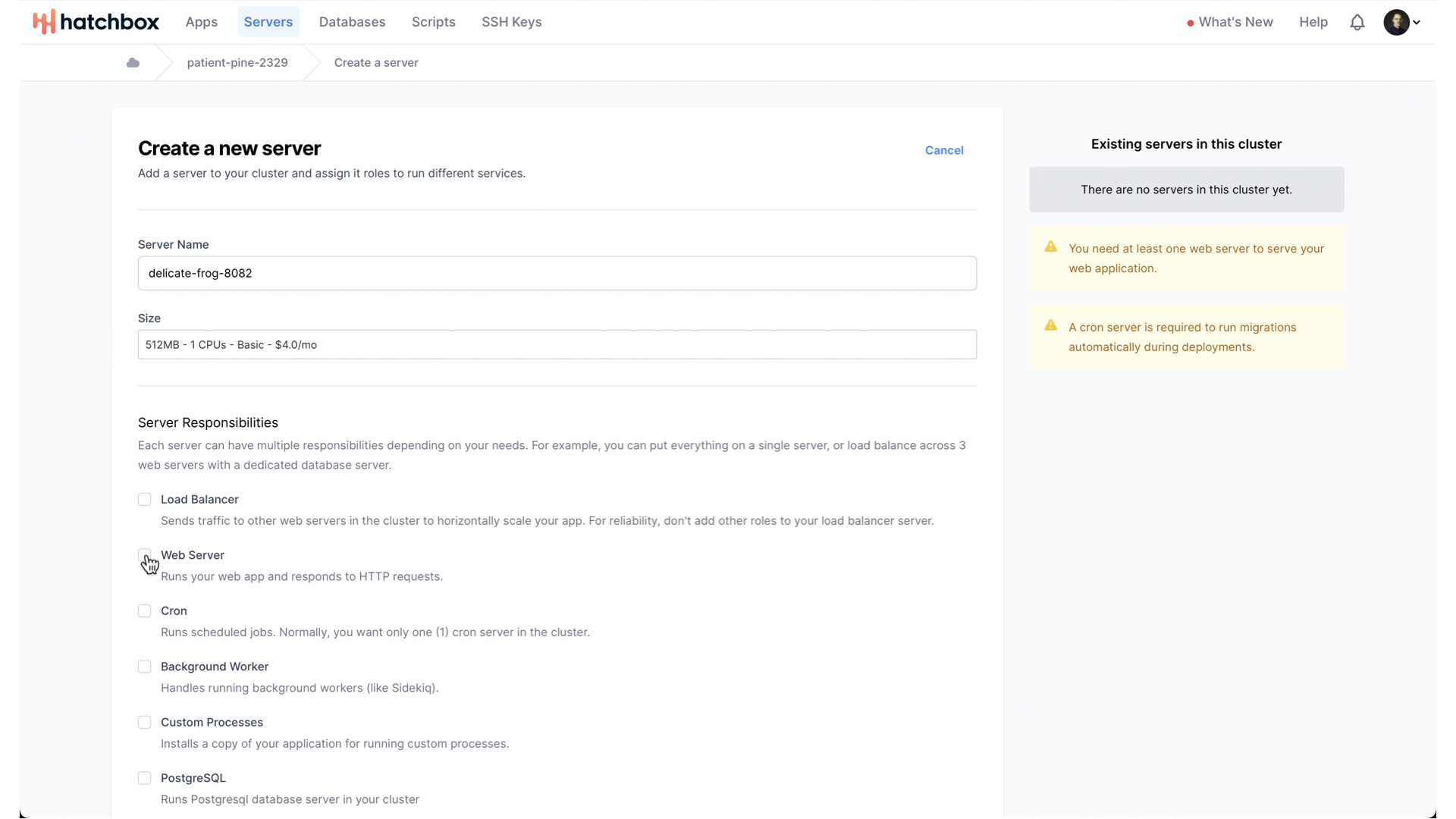
Let’s create a single server with both responsibilities.
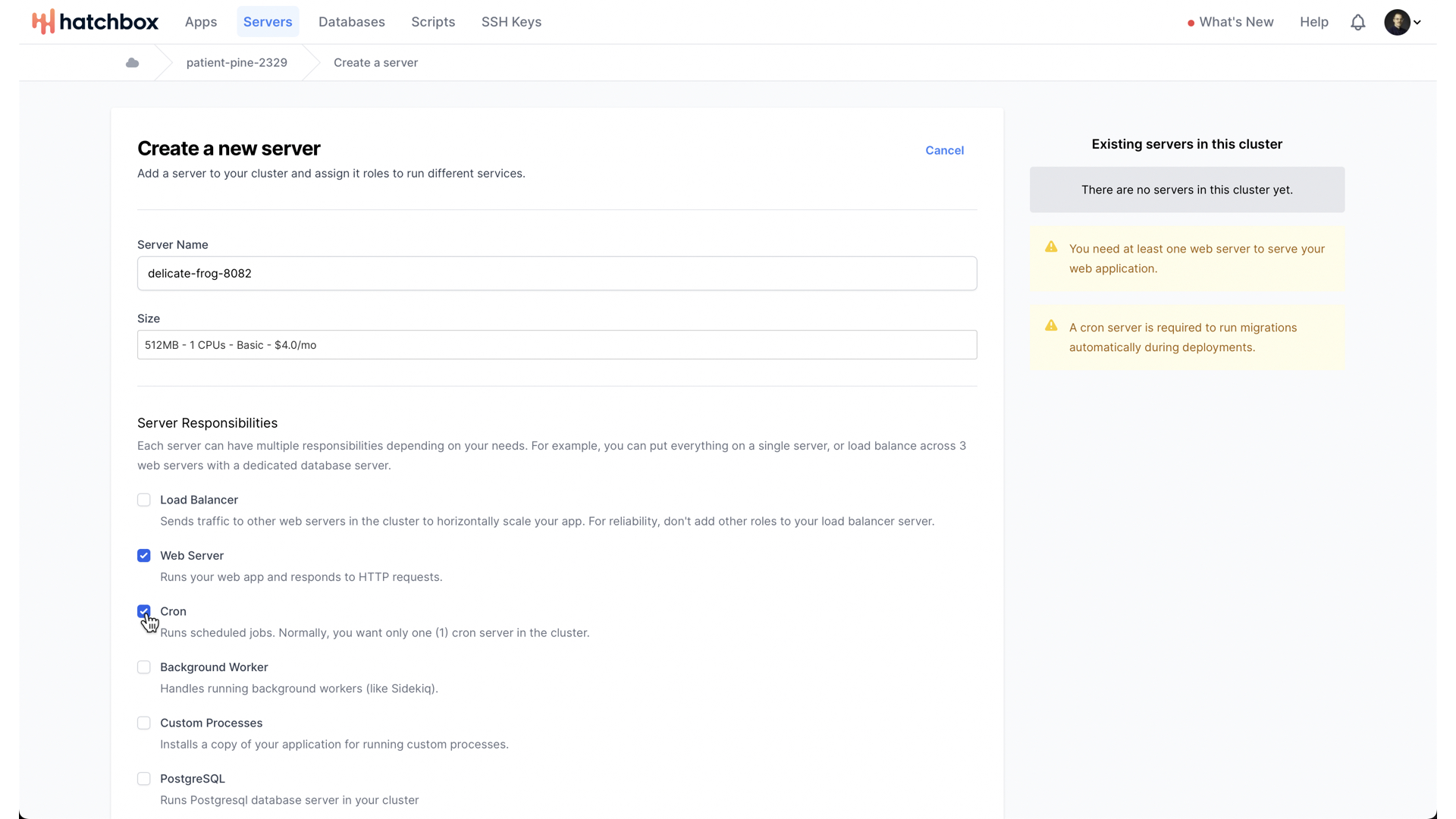
With that done, we can consider what size of server we want.
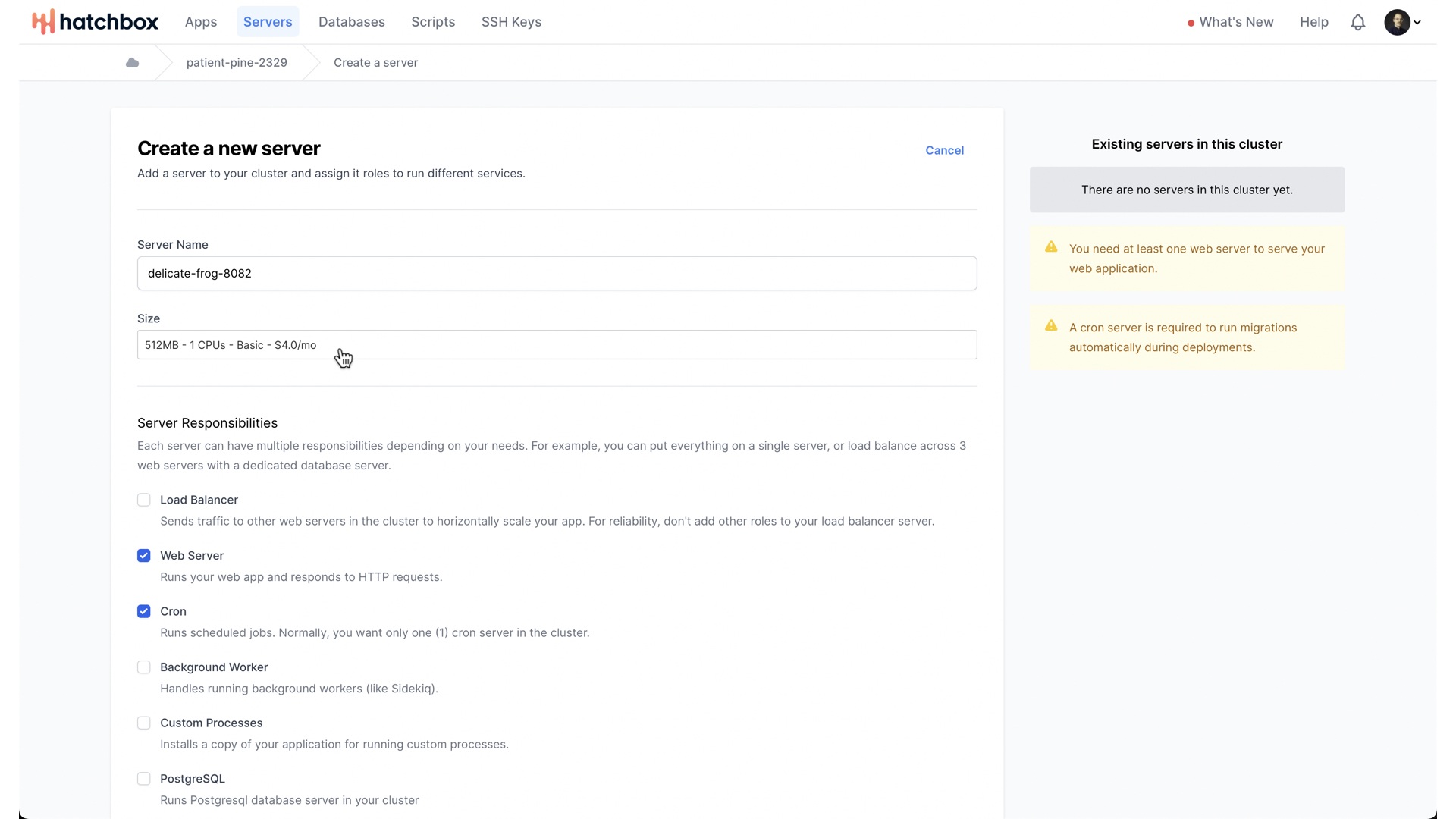
DigitalOcean’s Frankfurt region has a number of different server size options.
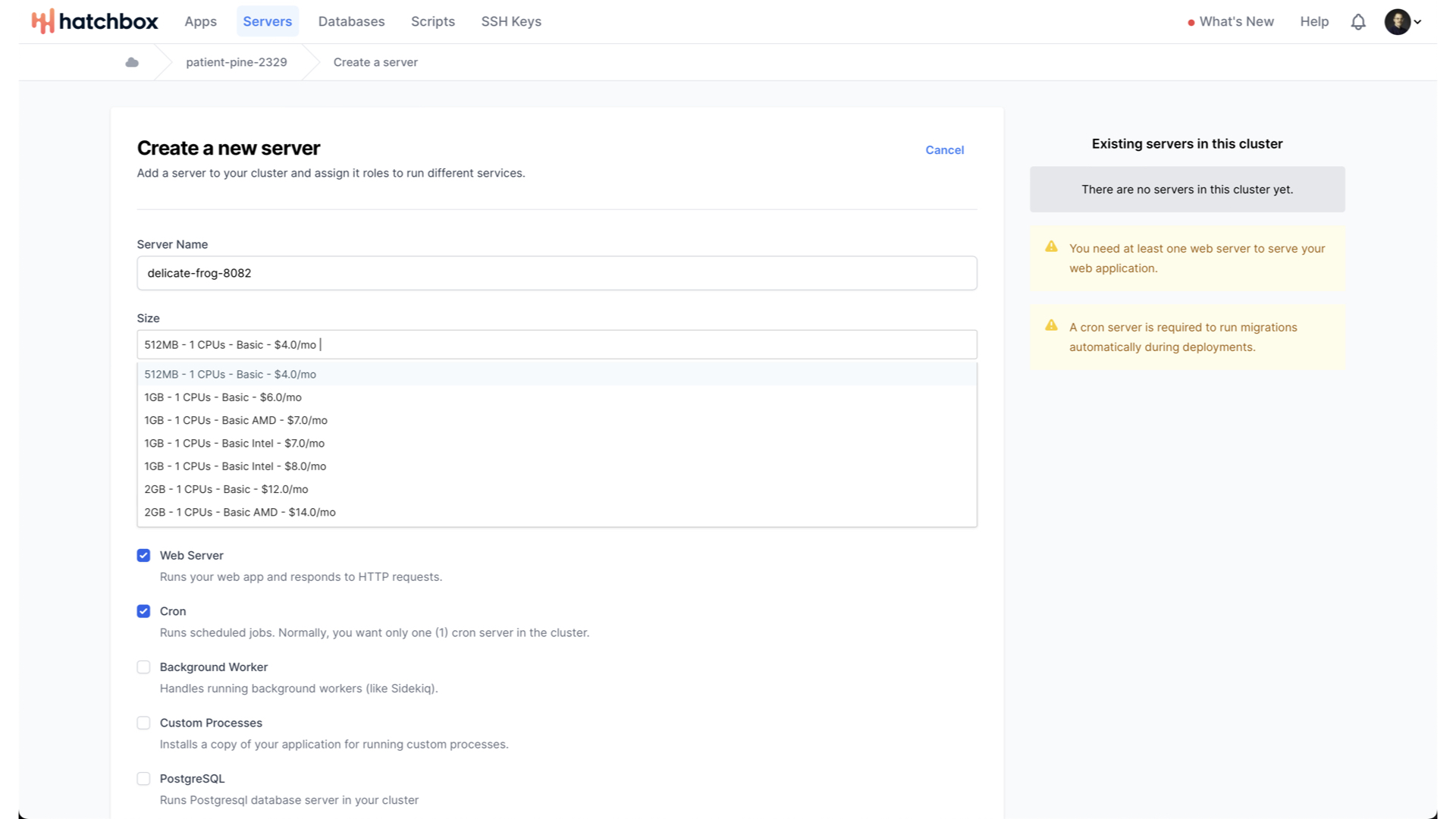
The largest option in this region goes up to 32GB of RAM, 8 CPUs, and is $192 a month. For our MVP though, let’s start with the smallest, simplest, cheapest option.
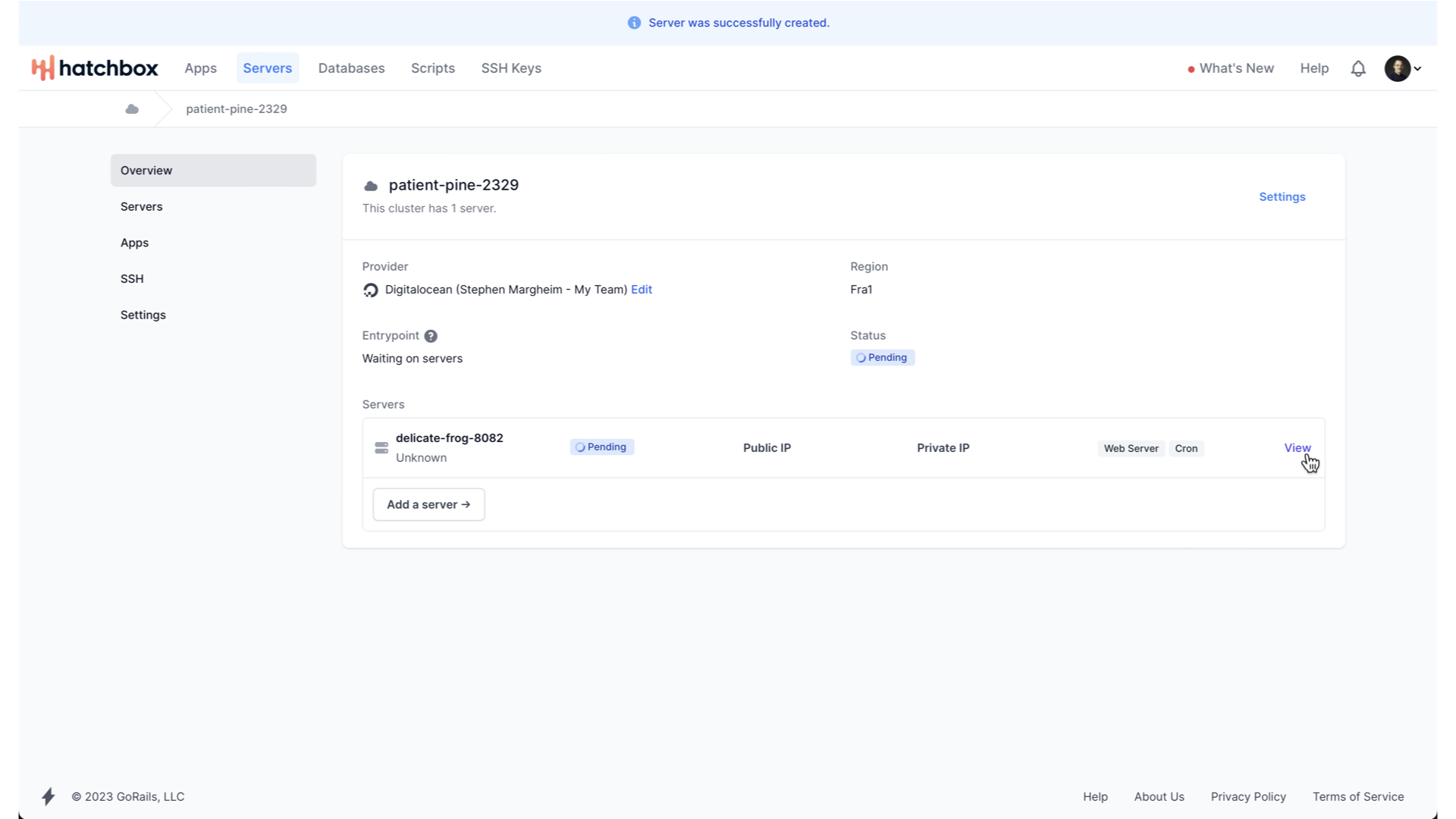
Now, Hatchbox will begin creating and provisioning our server.
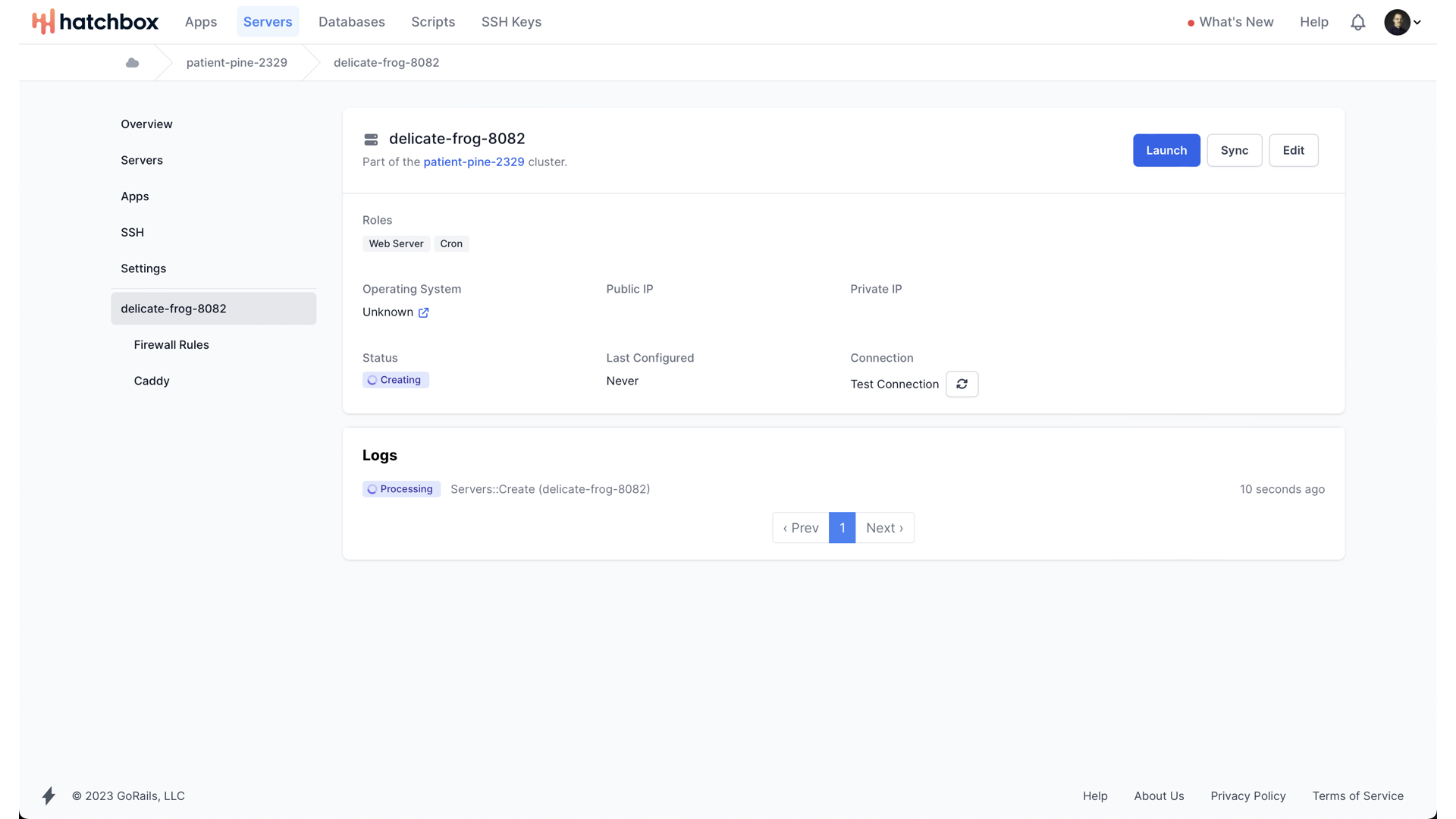
You can tail the logs of what precisely Hatchbox is doing if you’d like.
But once it has created the server on Digital Ocean, it will begin provisioning it.
That can take some time—in this case around 10 minutes, but once it is done, we can begin creating our App to deploy to this server on this cluster.
When we navigate to the “Apps” tab, we can create a new app.
You give the app a name and choose which cluster it should be deployed to.
We want our new app to deploy to our new cluster.
When we tell Hatchbox to create this app,
it will ask us for the repository information. If you are just starting, you can connect their GitHub app to your GitHub account.
Or, if you are using some other git host, or you have already installed their GitHub app
You can just choose that.
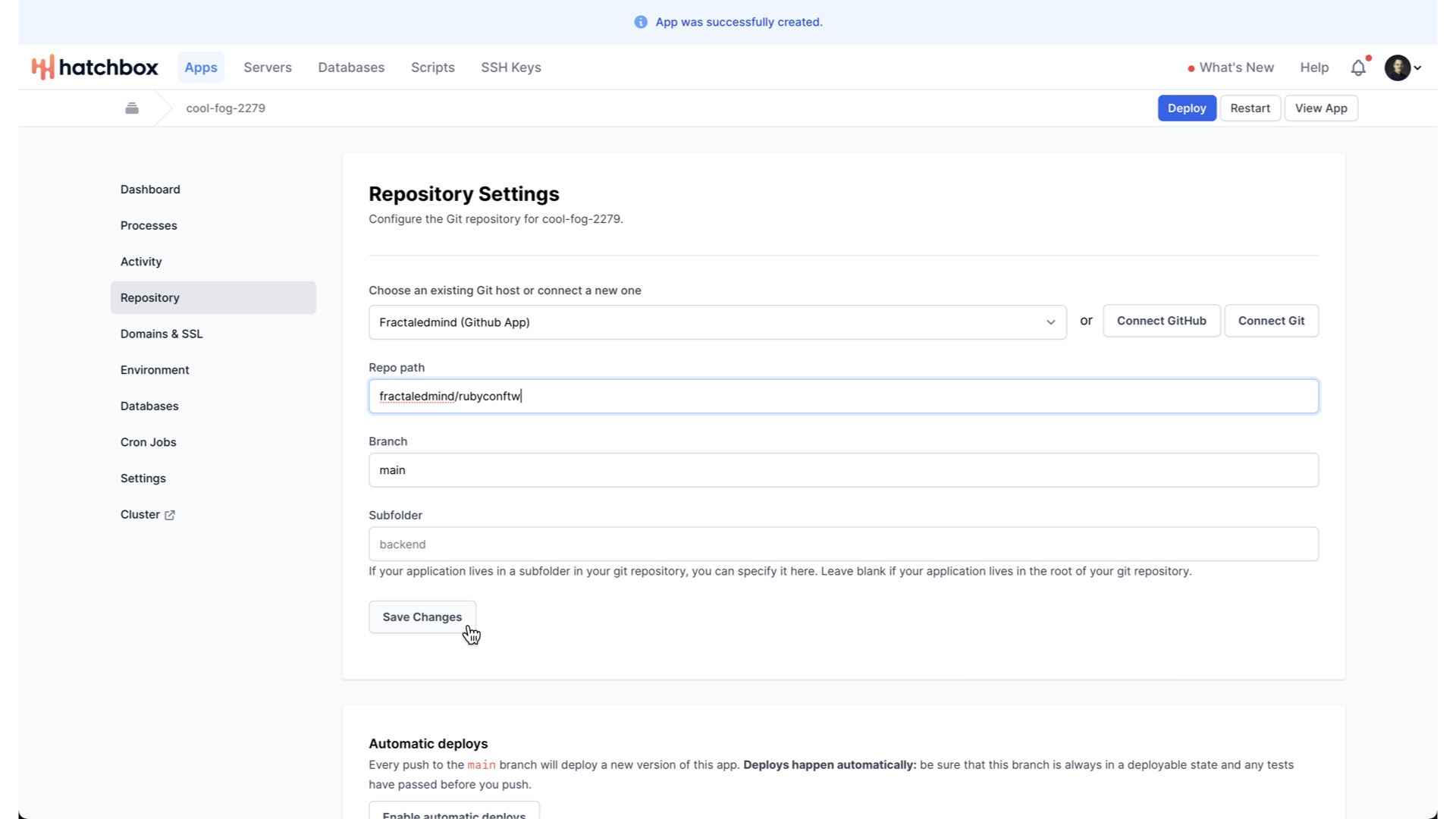
Provide the repo name and branch name, and that’s it.
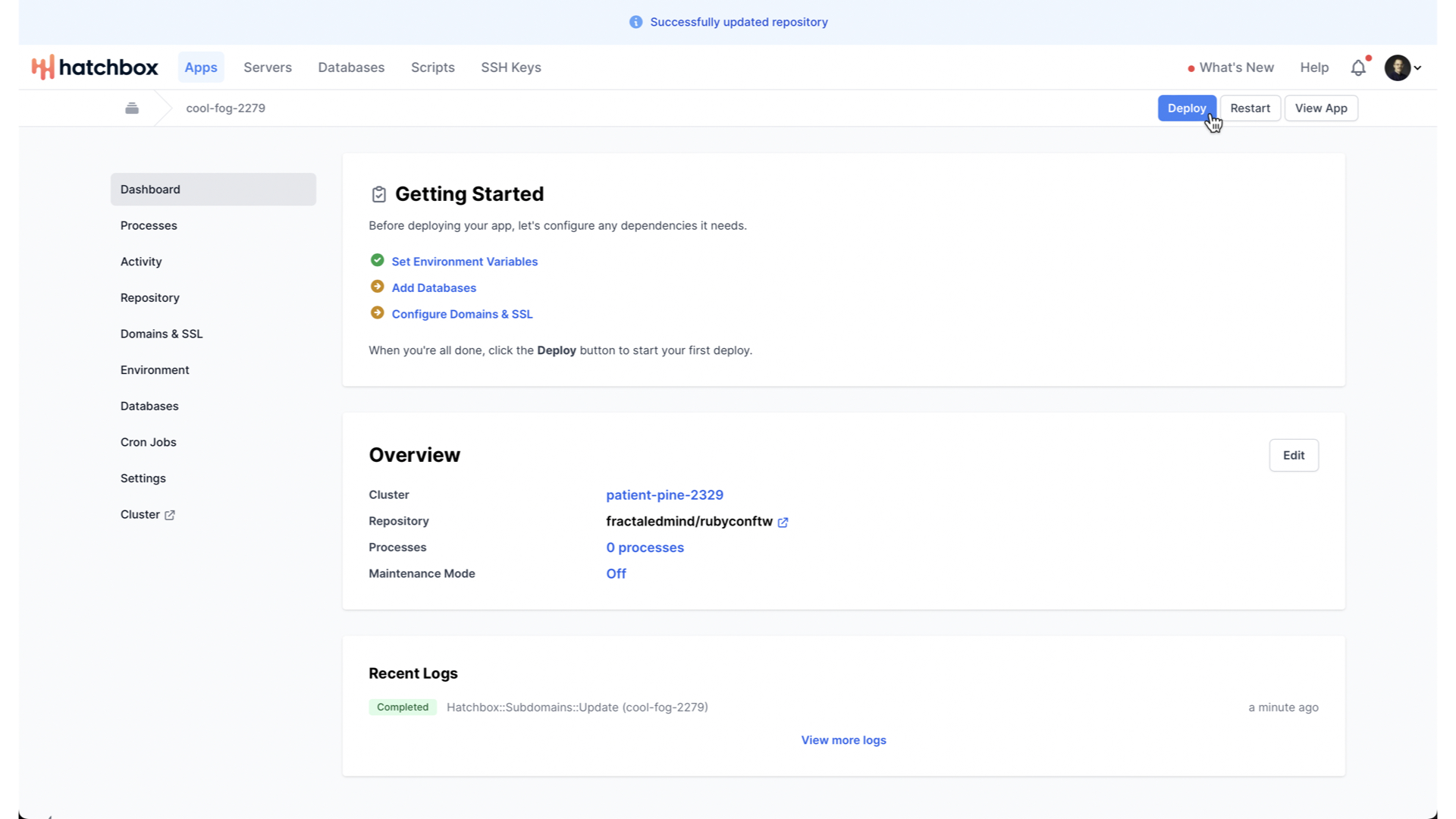
Now, we just need to deploy our new app to our new server.
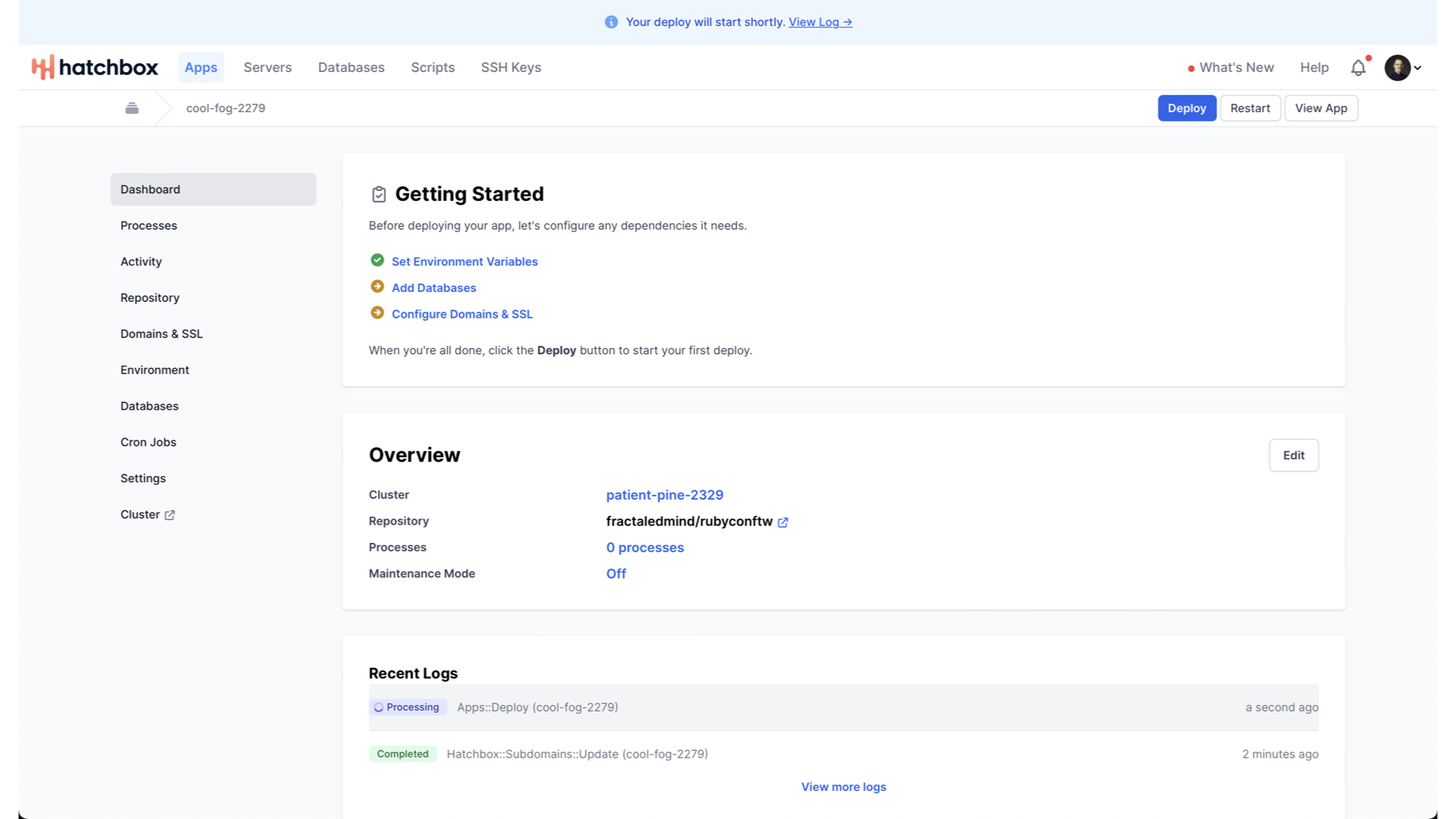
Again, Hatchbox handles the details here. And, again, you can tail the logs to see precisely what it is doing if you’d like.
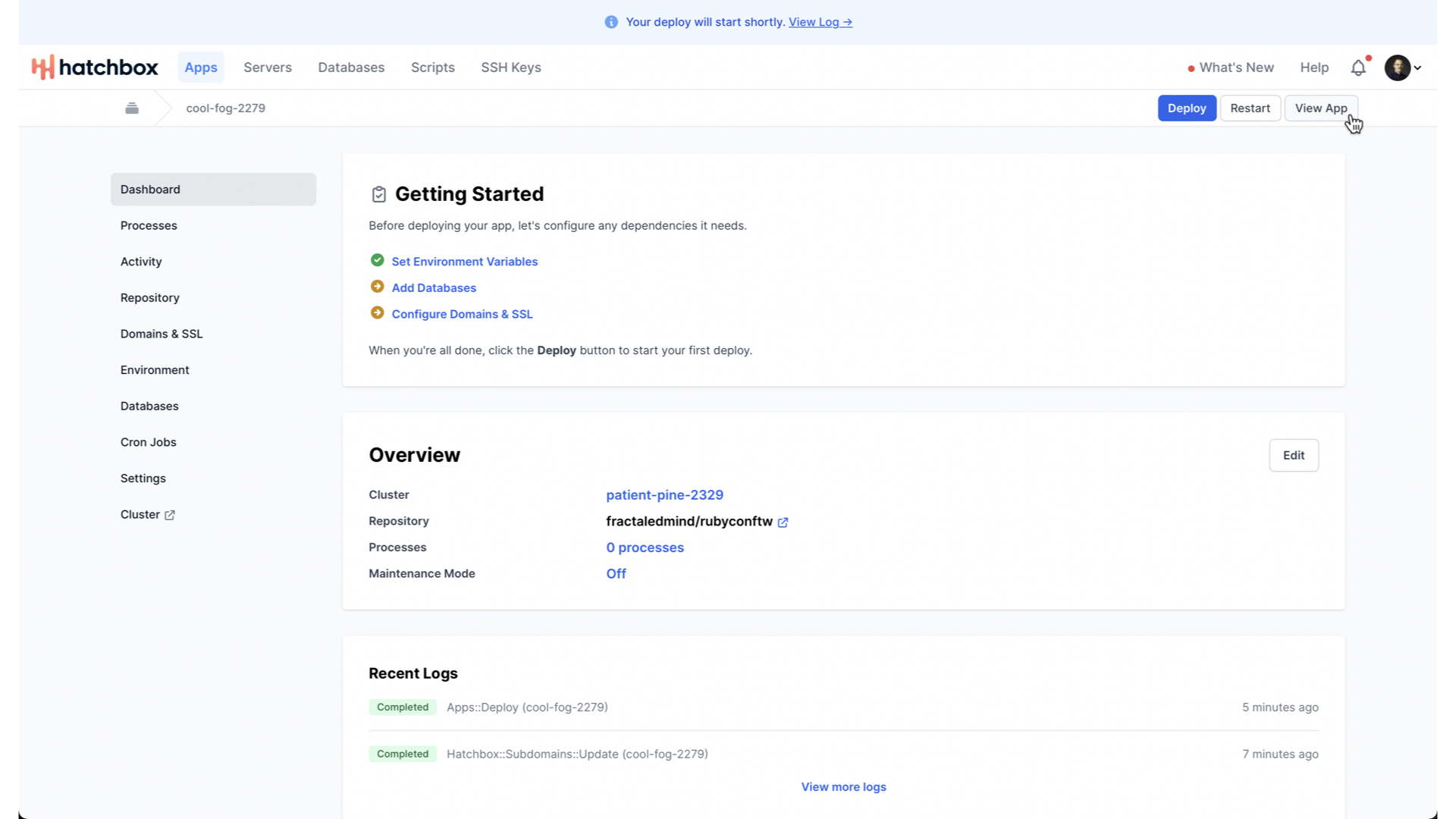
After a few minutes, your app will be deployed. You can now view that app running on a Hatchbox subdomain.

Congrats! As quickly and easily as that, you have a production SQLite on Rails application running. And I really want to emphasize just how quick and easy that was. In preparing this talk, I quite literally built and deployed this demo app in a single day. And I am running that app on a DigitalOcean droplet that costs $4 a month. And DigitalOcean gives you $200 dollars in credit when you first sign up. This is the beauty and promise of the majestic monolith—when your entire operational setup is embedded in your app repository, simple and consistent deployment becomes possible. Then, with a SQLite on Rails application, you can also make this simple deployment cheap. Great for MVPs and R&D projects. But I can already imagine what some of you are likely thinking: “Sure, it is technically running, but is it actually usable?” Let’s check. I’d love for anyone with a phone or laptop to head to demo.sqliteonrails.com and just click around. Does it feel useable? I’ll explore myself here on the conference wifi from Taipei hitting the server in Frankfurt.

We can also run our benchmarks to get a sense of our performance. I ran our different benchmarking scenarios against increasingly concurrent load. I ran each request twice as well to get a bit more variability for the averages. And, taking the overall average across every scenario and every concurrency setting, we get just over 20 requests per second.
Now, to be fair, I did run all of these benchmarks from my laptop sitting in Berlin. And we deployed our app to Frankfurt. Of course, the app will be slower from here in Taiwan. Let’s see how much slower.

I ran the balanced benchmark from my hotel last night. Again, I ran it against increasingly concurrent load and ran each scenario twice. Taking the overall average, we get 14 requests per second. Sure, these aren’t staggeringly large numbers, but we were all using the app and saw that it was completely useable. Let’s put this in context.
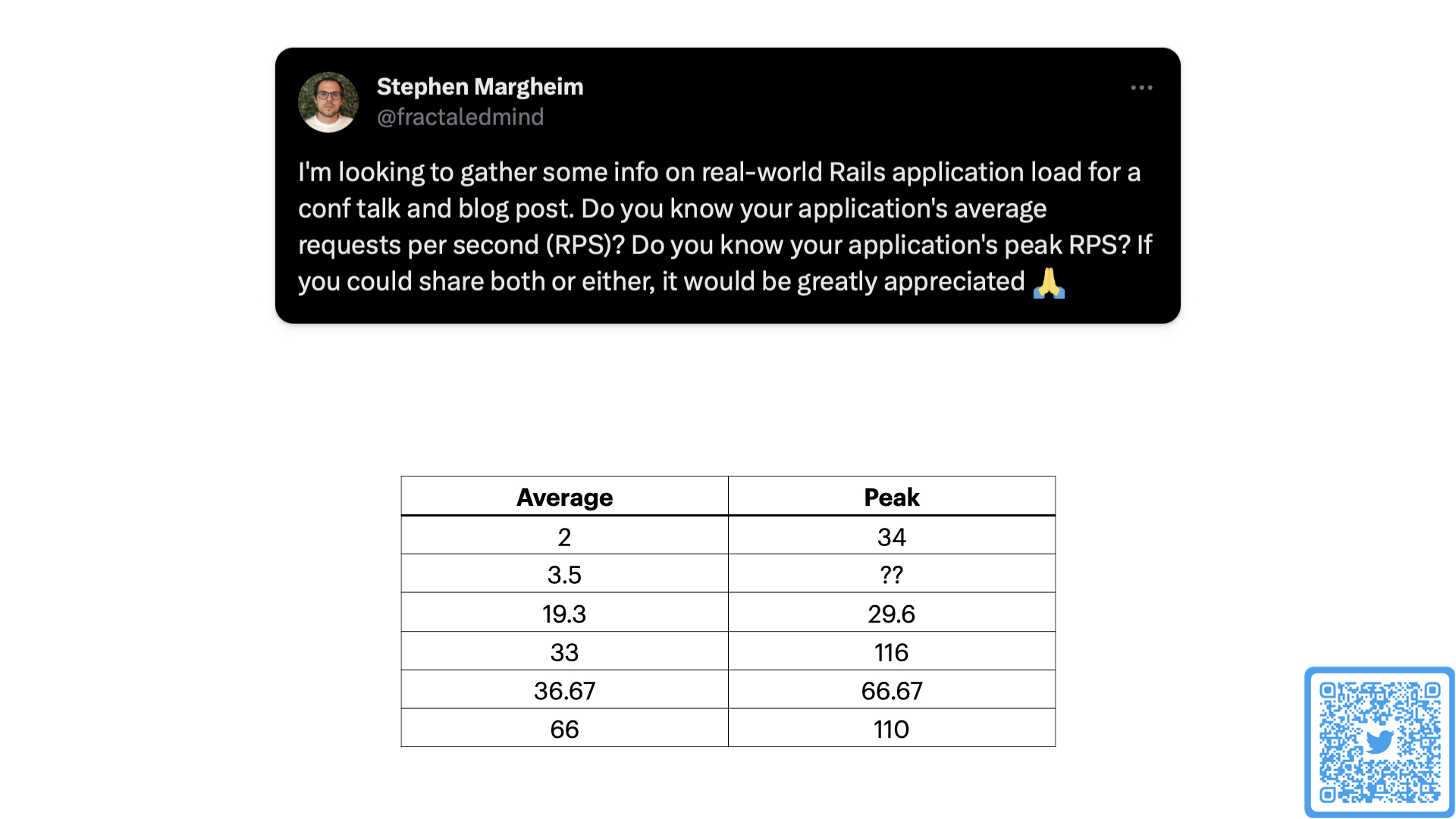
Earlier this week I asked for some anecdotal information about average and peak load for real, valuable production Rails apps. Here are the 6 replies I got. Does our demo work for the busiest half of these examples? No. But, the critical point here is that I built a working application, deployed to the smallest and cheapest server available, I’m running it in a single region on that tiny cheap server, and it is still totally useable. Useable enough to start making actual money.

It is so easy for us engineers to get lost in trying to do things the “right way” that we lose sight of the value and importance of just doing things at all. Especially when working on a side-project that isn’t just a learning exercise or an R&D project at work, don’t lose time to trying to have an app that handles large scale that it simply won’t get at first. Ship, and ship quickly. This is a completely vanilla Rails app deployed on a completely vanilla and tiny DigitalOcean droplet via a completely vanilla Hatchbox process. One day of work in total. One single day. This is the single most important point I hope you take home with you from this talk. A SQLite on Rails application is good enough. Ship it.
That being said, this hasn’t always been the case. The out-of-the-box experience for SQLite on Rails applications wasn’t production ready even 3 months ago. So, there is some legitimacy to the presumption that people have had that SQLite can’t back production web applications. I hope I’ve shown you, though, that today it can.

So, I want to briefly explain why our vanilla Rails app was useable in production on day one, because that certainly wasn’t always the case. Starting with Rails 7.1, we are applying a better default configuration for your SQLite database. These changes are central to making SQLite work well in the context of a web application. And the reality is, if you had tried to run a SQLite on Rails application in production before Rails 7.1, you likely did have a more difficult time and your performance wasn’t at a baseline of good enough. So I understand why and how this belief that SQLite can’t work in production for your Rails application came from. But, it is important that we don’t let our opinions formed in the past go unchallenged in the present. We have been doing a lot of work to make the out-of-the-box experience of SQLite on Rails applications noticeably better. If you’d like to learn more about what each of these configuration options are, why we use the values we do, and how this specific collection of configuration details improve things, I have a blog post that digs into these details.

Another factor in ensuring that the default experience of SQLite on Rails applications is high quality is the default compilation settings of the SQLite executable itself. Mike Dalessio is the current maintainer of the sqlite3-ruby gem, and he and I have worked together to find the minimal default configuration for the executable that has the best default performance experience. When you install SQLite thru the Ruby gem, it is compiled to use the write ahead log and include the full text search extension. Again, more details on compilation settings and why we use the values we do are in my blog post.

Now, that being said, we all are hoping that our side-projects will take off somehow to some degree, so we want to know that a SQLite on Rails application can “scale”. And while I do genuinely believe that 10 to 20 requests per second is good enough for shipping an MVP on the smallest cheapest server possible, this stack isn’t viable if it can’t grow as our app and usage grows. So, let’s talk some about how to enhance the power of our SQLite database and our SQLite on Rails application. Plus, I want to show you some of the ways you can take advantage of SQLite’s unique design to make your life and your application better.
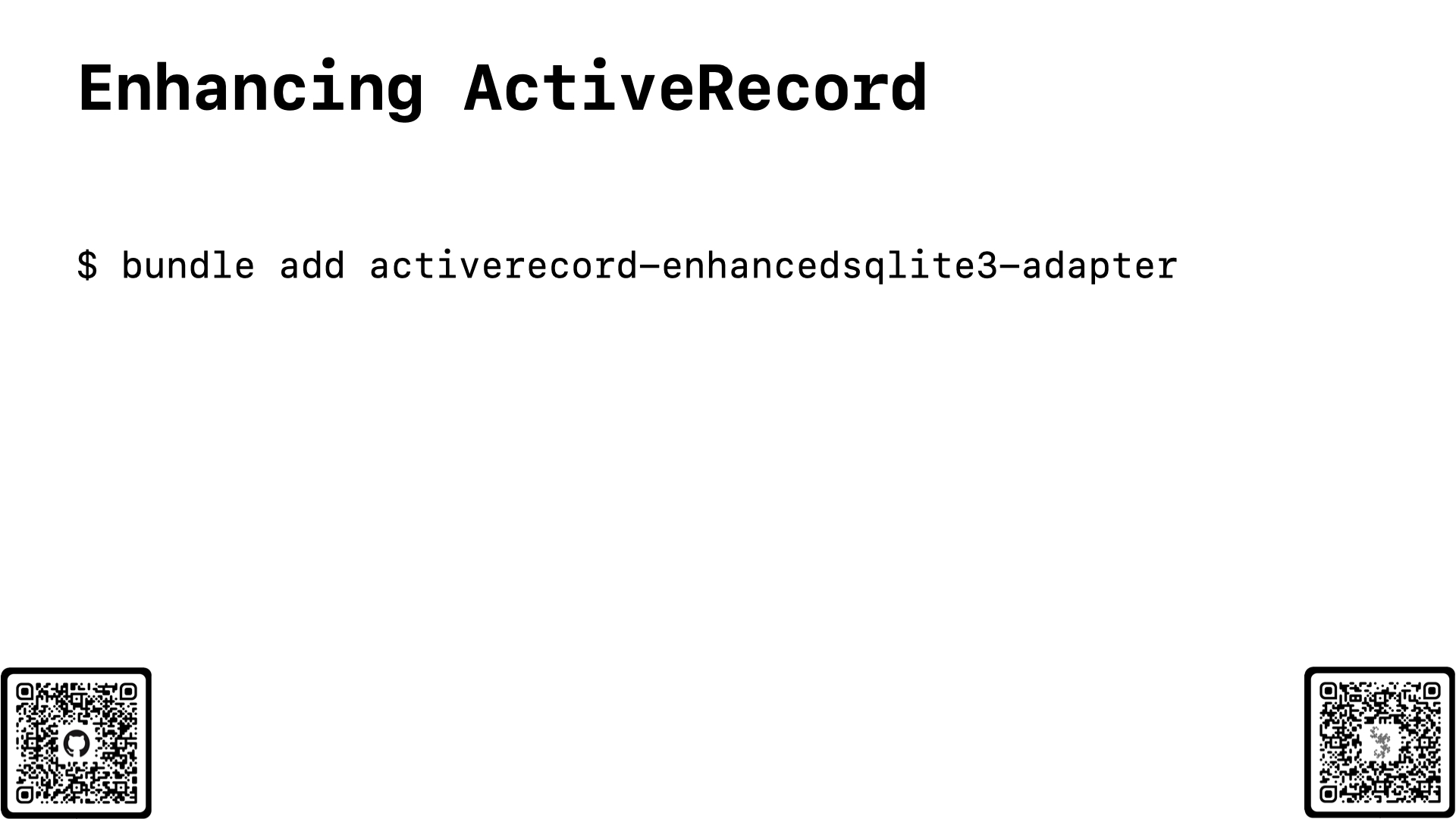
The first thing you should do when you start “scaling” your app is to install the enhanced adapter gem. While the default configuration for a Rails app is notably better today than it was even just 3 months ago, Rails moves relatively slowly, and there are improvements that we as a community have proven out that aren’t yet in Rails core. Or, there are some improvements that are currently in Rails core, but we want to make them available to all Rails apps at least on version 7.1. So, I created the enhanced adapter gem, which when added to your application will automatically, well, enhance your SQLite database.

How does it enhance it? Well, in 5 ways. It ensures that some ActiveRecord features are present that weren’t released as a part of Rails 7.1 (tho both should be in Rails 7.1.3, and both are (as of yesterday) currently in Rails main). It then also powers up the database.yml file to allow for you to fine-tune your SQLite configuration and also load SQLite extensions, directly from the database.yml file. But, probably most importantly, it improves how your SQLite on Rails application handles concurrent load. I want to highlight two of these features today, to demonstrate some of the more powerful and useful enhancements that the gem provides.

First, it is now easy to install and load SQLite extensions into your app. In this example, I am installing and loading the vector similarly search extension for SQLite. Yes, you can integrate vector similarly search into your SQLite on Rails application. This makes it possible to implement a Retrieval-augmented generation (RAG) AI feature into your Rails application. pgvector isn’t the only kid on the block. For those of you in Andrei Bondarev’s talk this morning on catching the AI train, this should be of particular interest.

But, my favorite feature of the gem is its improved concurrency support. And why is this important? The first lever you should pull as you start to scale your application is increasing concurrency. The simplest first thing to do is to scale your server to one that has multiple cores such that Puma naturally runs in clustered mode, spinning up multiple Puma workers to server your app’s requests. The reality is that the out-of-the-box experience for SQLite on Rails applications today isn’t well suited for concurrent workloads. Let’s do some quick local benchmarking to see how.

So, what’s going on here? How is the enhanced adapter so radically improving how our application handles concurrent workloads? I don’t have time to go into great detail here, but you can read my recent blogpost on the topic linked via the QR code. The short explanation is that the gem defines a custom timeout handler that will release the GIL while waiting for a connection. Plus, we ensure that all transactions will use this custom timeout handler. And, this feature will eventually be upstreamed into Rails, but you can get it today via the enhanced adapter gem.

Beyond the default compilation configuration, we can enhance the compilation settings for the SQLite executable for our specific application as well. SQLite has lots of compilation options. But, for modern web applications, these are the compilation options that the SQLite documentation itself recommends. They are particularly useful when you need to extract every possible bit of performance out of SQLite for your app.

Beyond just enhancing the default SQLite setup, we can also extend how our app uses SQLite, taking advantage of some of its unique characteristics.

For example, this is one of my favorite developer experience improvements that SQLite makes so easy. You can get isolated databases for each git branch in your repository, so that you never get schema conflicts as you checkout different branches throughout your workday. And I just love that this massive improvement to your daily development experience is literally just a 2-line change.

Plus, one of the most important details for a production SQLite on Rails system is to have a backup procedure in place. The Litestream utility allows you to stream every update to your SQLite database (or databases) to any of a number of bucket storage systems. And, as of Wednesday, there is now a Ruby gem that will install the executable into your app. Then, you can run the installer to get it integrated into your Rails app as well.

Finally, you can take advantage of SQLite’s speed and simplicity to simply use SQLite as your backend for all of the Rails components that need some kind of persistent data

Litestack offers SQLite-backed, fine-tuned implementations of each of these data-bound components. This allows you to keep the operational simplicity of your majestic SQLite on Rails monolith while also building out a truly full-featured Rails application.

In the end, I hope that this exploration of the tools, techniques, and defaults for SQLite on Rails applications has shown you how powerful, performant, and flexible this approach is. Rails is legitimately the best web application framework for working with SQLite today. The community’s growing ecosystem of tools and gems is unparalleled. And today is absolutely the right time to start a SQLite on Rails application and explore these things for yourself.

This is an edited transcript of a talk I gave at RubyConf Taiwan 2023. You can watch the full talk on YouTube below.
